
2017년에 발표된 Attention Is All You Need는 Transformer 모델을 제안한 논문이다. 이 모델은 기존의 RNN이나 LSTM을 사용하지 않고, 오직 Attention Mechanism만을 사용하여 Sequence Data를 처리한다. 지금부터 NLP 분야에 혁신적인 발전을 일으킨 Transformer에 대해 알아보자.
Attention Mechanism
Transformer에서 가장 중요한 개념인 Attention은 한 단어와 다른 단어 사이의 관계를 모두 파악할 수 있어 특정 몇 단어 간의 관계가 아닌 모든 단어와 대응되는 관계를 파악한다. 이렇게 Sequence Data의 순서 정보에서 벗어나 학습하여 RNN, LSTM 등에서 문제 되었던 Long Term Dependency (데이터를 Sequential하게 처리하여 먼 과거 정보가 현재 시점에 영향을 끼치지 못하는 문제)를 해결할 수 있게 되었다.
Transformer
Transformer는 Recurrent 형식의 신경망이나 Convolution 기법을 사용하지 않고 Attention Mechanism 만을 사용하여 Sequence Data를 처리하는 최초의 Neural Network 이다.
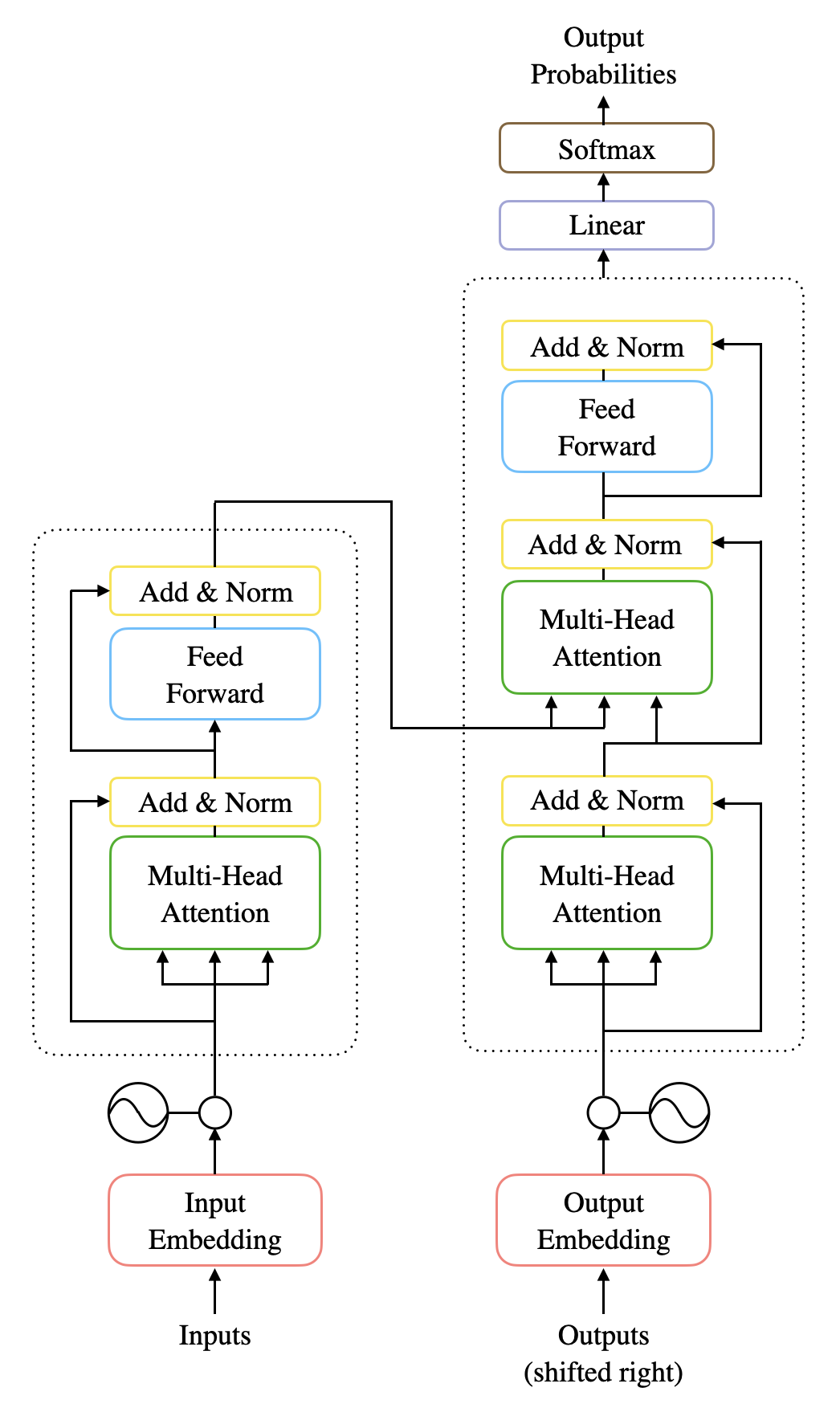
모델 구조는 크게 Encoder-Decoder로 나누어 볼 수 있고, 여러 Sequence Model 처럼 Encoder에선 입력 데이터의 관계를 학습하고 Decoder에선 학습한 관계를 통해 최종 결과를 출력한다.
지금부터 본격적으로 입력 데이터를 처리하는 것부터 최종 출력 결과를 내보내는 과정을 살펴보도록 하자.
Input Embedding + Positional Encoding
- Input Embedding
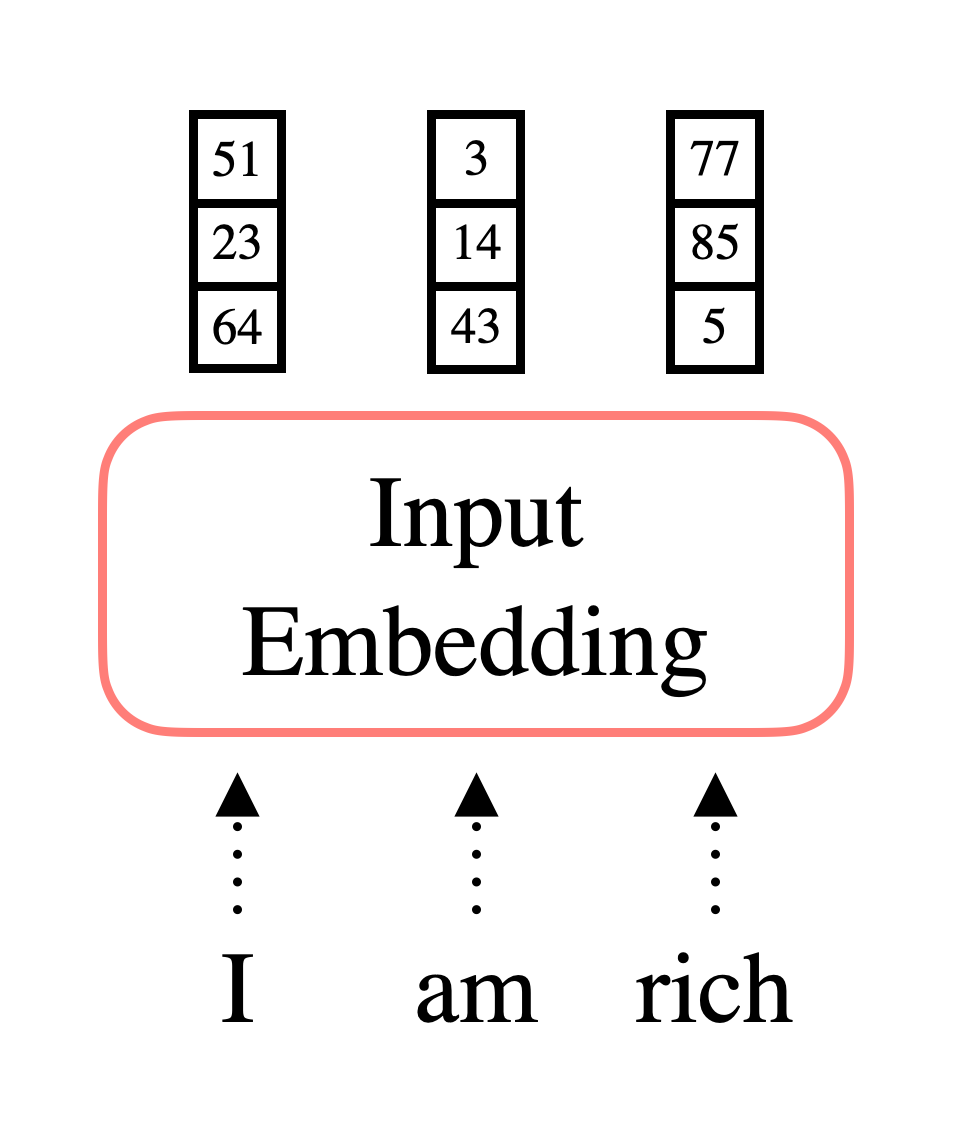
모델이 데이터를 입력 받으면 가장 먼저 처리하는 과정이 Embedding Vector로 변환하는 것이다. 단어 하나 하나를 vector(숫자)로 변경해 전체 데이터를 행렬로 표현하는 것인데, Neural Network는 숫자 데이터를 학습하기 때문에 이같은 과정을 수행하게 된다.
- Positional Encoding
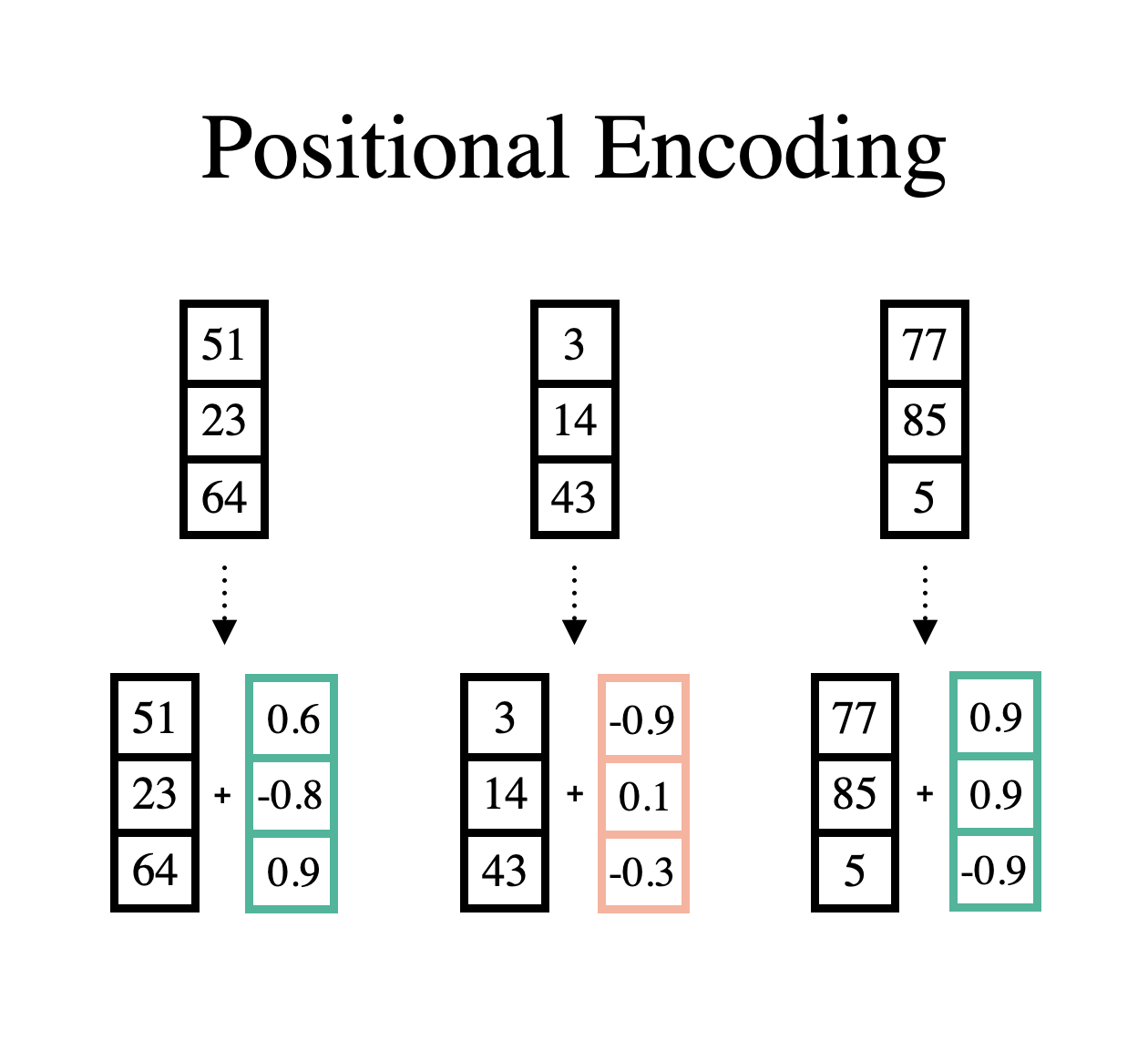
다음으론 Input Embedding Vector에 위치 정보를 추가하는 Positional Encoding 과정을 거치게 된다. 기존 Recurrent Network는 Sequence 순서에 의존한채 학습이 진행되기 때문에 위치 정보를 따로 추가할 필요가 없었지만 Attention Mechanism은 Sequence 순서에 상관없이 전체적으로 데이터 관계를 파악하기 때문에 위치 정보를 추가하는 작업이 꼭 필요하다.
위치 정보를 추가하는 방법은 간단하다. Input Embedding에 같은 크기의 vector를 더해주기만 하면 된다. 단, 이때 아래 두 가지 조건을 만족해야 한다.
- Input Data 혹은 Input Data의 길이에 상관없이 Index를 기준으로 같은 Index에는 항상 같은 vector를 더해주어야 한다.
- 너무 크지 않는 vector를 더해주어야 한다.
1번의 경우는 Sequence가 변하더라도 위치 Embedding을 동일하게 만들기 위함이고, 2번은 너무 큰 위치 값은 단어 정보보다 위치 정보가 상대적으로 커져 단어 간의 상관관계나 의미를 유추할 수 없게 만들기 때문이다.
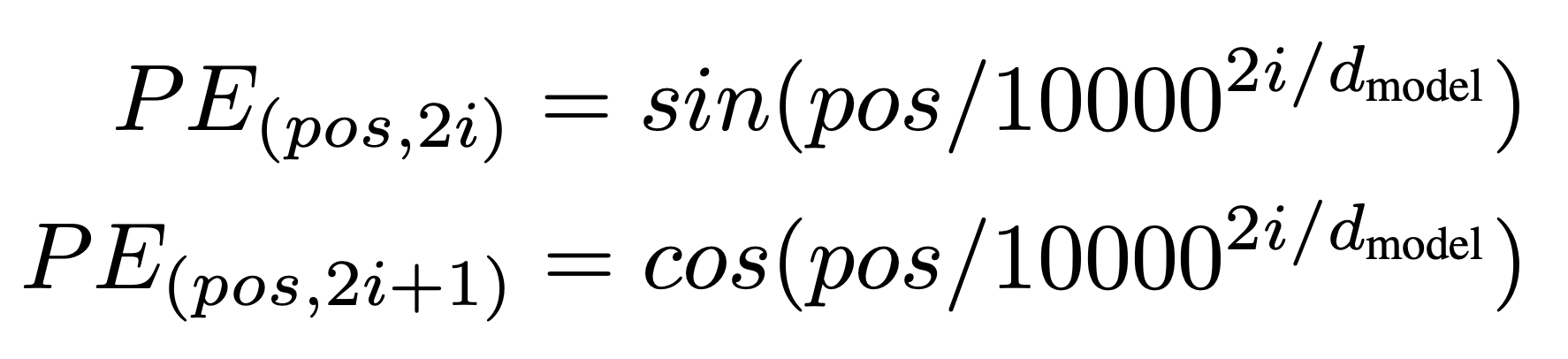
이런 조건을 만족시키는 vector를 얻을 수 있는 방법은 바로 주기 함수($sin, cos$)를 사용하는 것이다. -1~1 사이를 반복하는 주기 함수를 사용하여 값이 너무 커지는 것을 방지하고 vector 차원마다 다른 주기의 $sin, cos$ 함수를 두어 위치 값이 겹치지 않도록 해준다.
Encoder
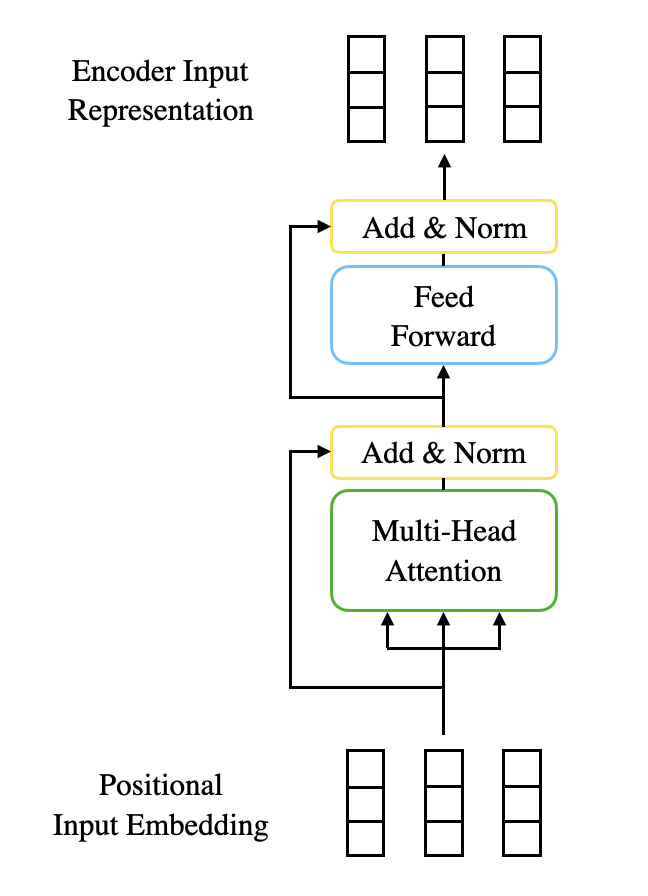
이렇게 Input Embedding에 위치 정보를 더한 Positional Input Embedding Vector를 계산하면 이를 Encoder의 입력으로 사용해준다. 그 뒤 총 2개의 sub-layer를 거쳐 최종 Encoder Input Representation Vector를 출력하게 된다.
Multi-Head Attention
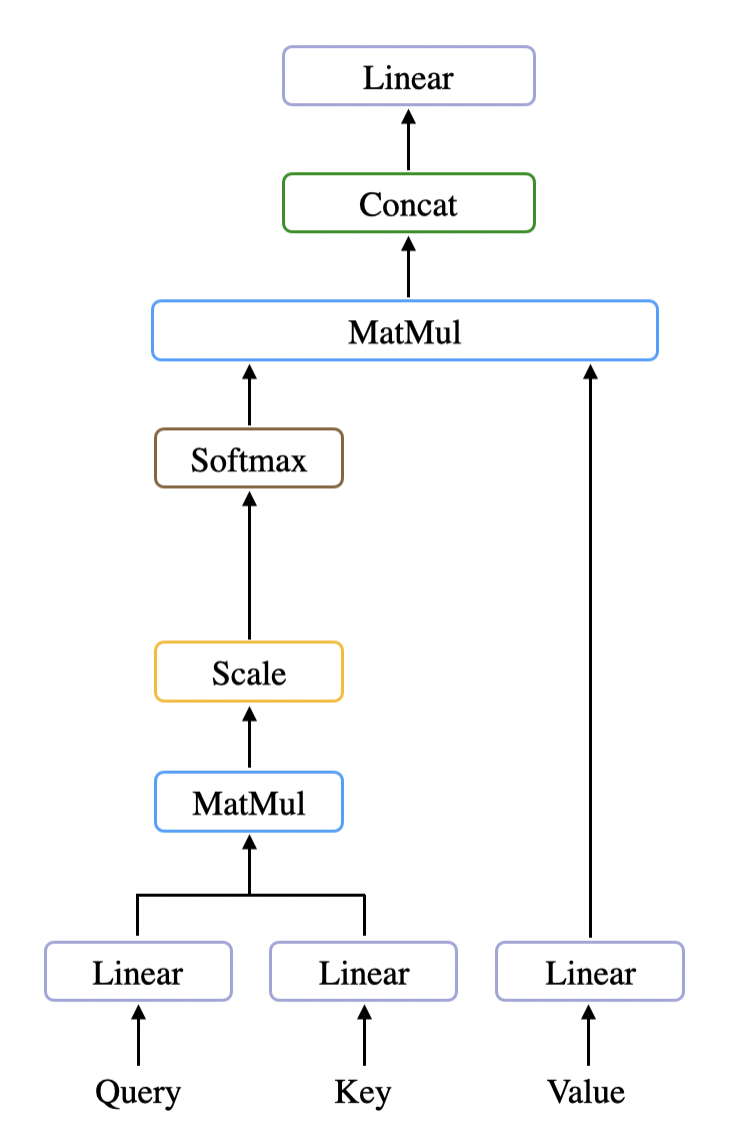
첫 번째 sub-layer는 여러 개의 Self-Attention 연산으로 이루어진 Multi-Head Attention이다. 해당 레이어에서 입력 문장 속 단어들의 관계를 학습하게 된다.
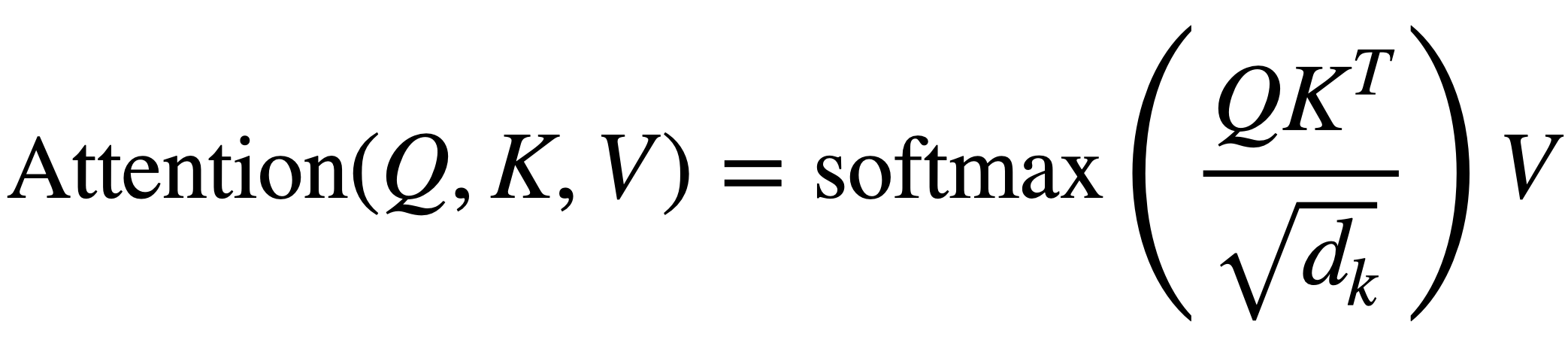
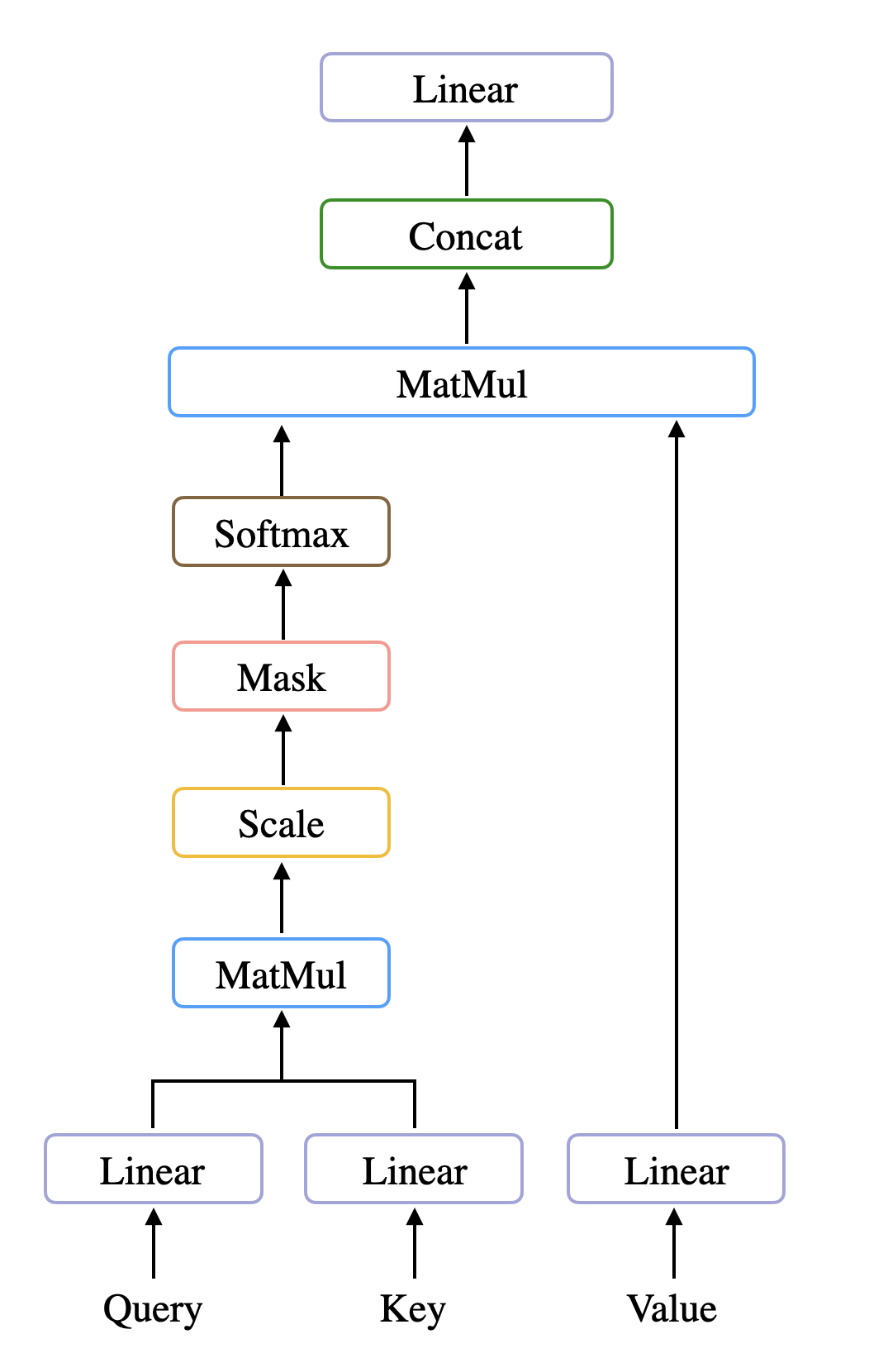
Self-Attention을 수식으로 나타내면 다음과 같다. Input Sequence의 선형 변환을 통해 만들어진 Query, Key, Value를 계산해 Attention 연산을 수행하게 된다. 각 연산이 어떤 의미를 가지는지 차례대로 살펴보도록 하자.
- Query, Key, Value
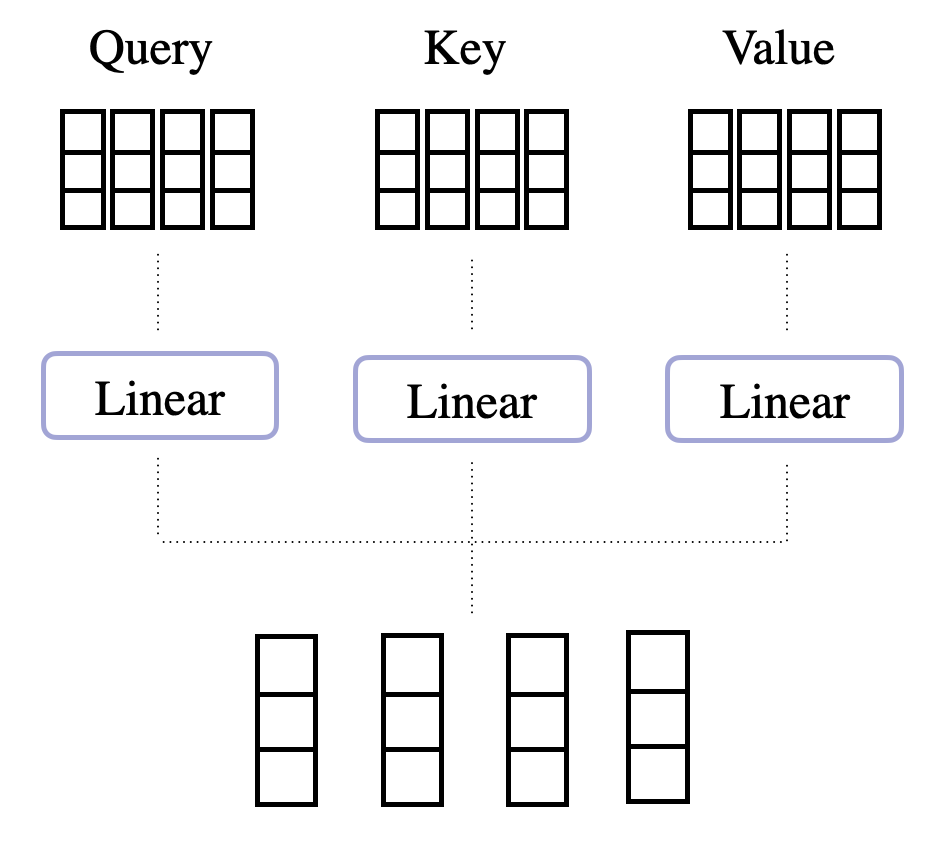
Multi-Head Attention은 Input Embedding을 선형 변환한 Query, Key, Value를 Input Data로 사용한다.
Query는 현재 단어(token)가 Input Sequence에서 어떤 걸 찾고자 하는지 나타내는 정보로, 문장에서 현재 단어와 다른 단어들 사이 어떤 정보를 가지고 있는지, 어떤 관련성을 띄는지 찾고자할 때 사용한다. Key는 Input Sequence 내 단어들이 가지고 있는 특성이나 특징을 나타낸다. 따라서 Query가 어떤 정보를 찾고자 할 때 Key는 각 단어들이 가지고 있는 특성을 나타내어 해당 정보를 찾을 수 있도록 구성되어진다. 마지막으로 Value는 각 단어가 가지고 있는 정보를 나타내는 것으로, Key가 각 단어의 특성을 나타낼 때 Value는 그 특성에 해당하는 실제 내용을 담고 있다.
앞서 언급했 듯이 Query, Key, Value는 Input Embedding를 선형 변환한 것으로, 각각 다른 가중치 값을 곱해 계산된다. Input Embedding의 크기가 $(N,d_{\text{model}})$인 행렬이라면($ Sequence 길이, $d_{\text{model}}$ = Embedding 차원), Query, Key, Value는 Input Embedding에 세 개의 가중치 값을 곱해 생성되므로 아래와 같은 크기를 가지는 행렬이라 정의할 수 있다.
$\mathbf{Q=XW_Q, K=XW_K, V=XW_V}$
여기서 $W_Q, W_K, W_V$는 각각 크기 $(d_\text{model}, d_K)$, $(d_\text{model}, d_K)$, $(d_\text{model}, d_V)$인 가중치 행렬이며, 일반적으로 $d_K$와 $d_V$는 $d_\text{model}$과 같은 차원일수도, 다른 차원일수도 있다.
- Dot Product of Query & Key
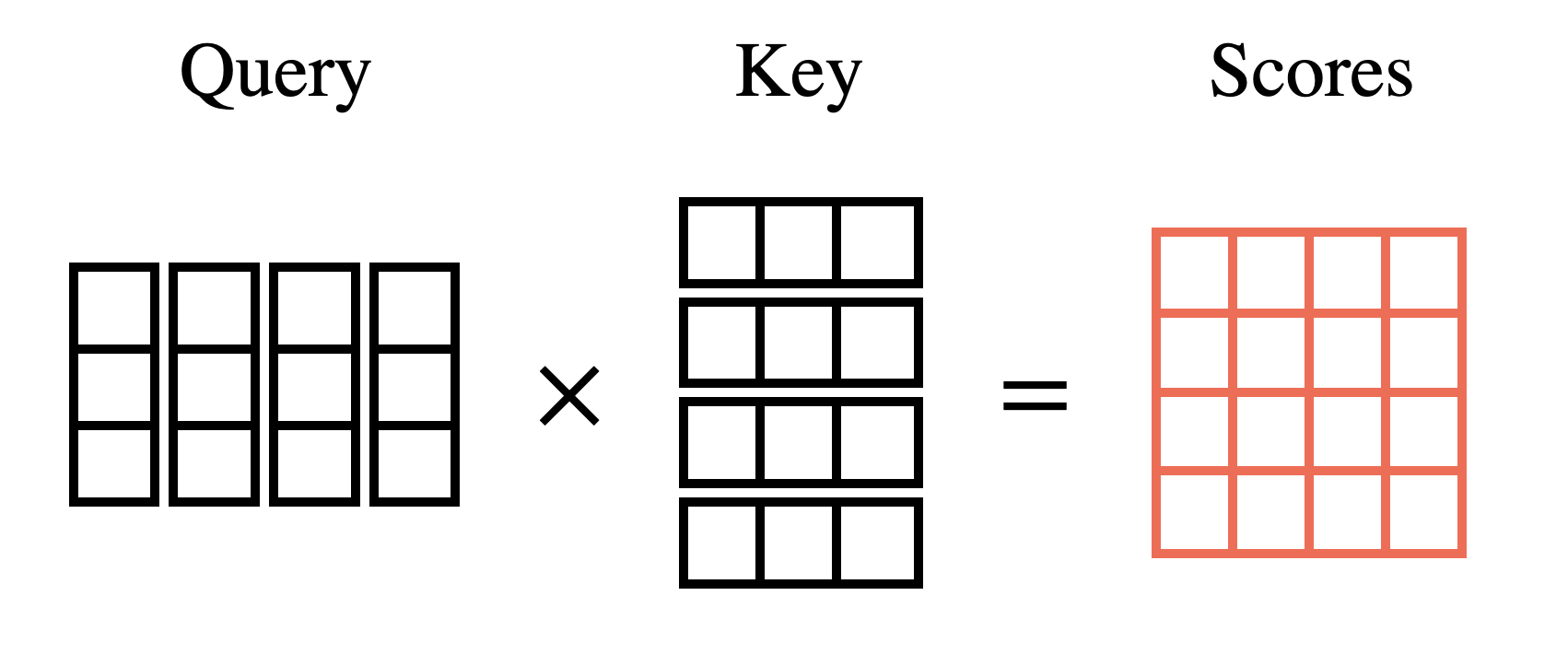
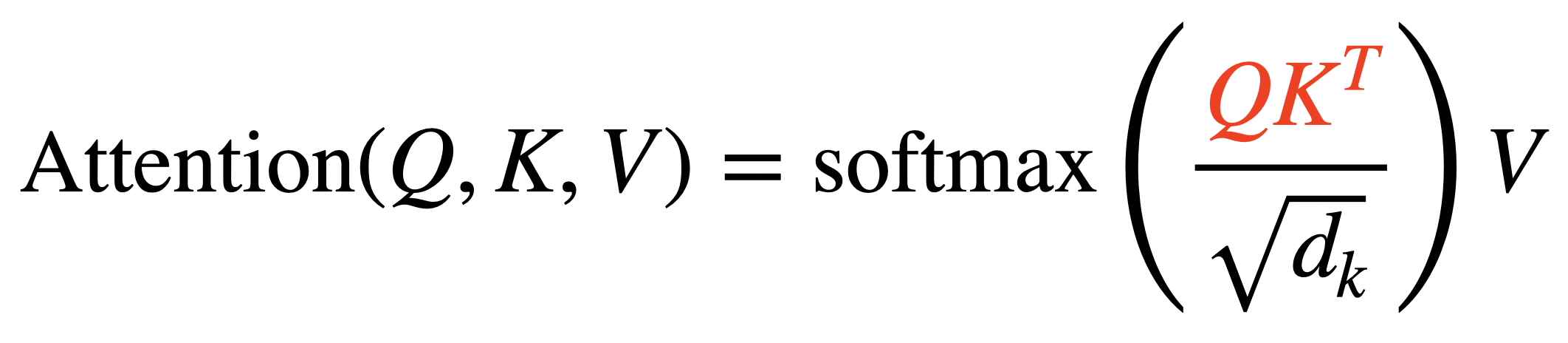
이후 수행되는 연산은 Query와 Key의 Dot Product 이다. Score Matrix를 생성하여 각 단어 간의 중요도를 계산하는 작업을 거친다. 모든 단어들은 자신들만의 점수를 가진다. 이건 매 time step 마다 다른 단어와 얼마나 연관 있는지 혹은 다른 단어와 얼마나 유사한지 나타내는 점수이다. 이 점수가 높을수록 중요한 단어임을 나타내고, 모델은 점수가 높은 단어에 집중하게 된다.
- Scaling Down the Attention Score
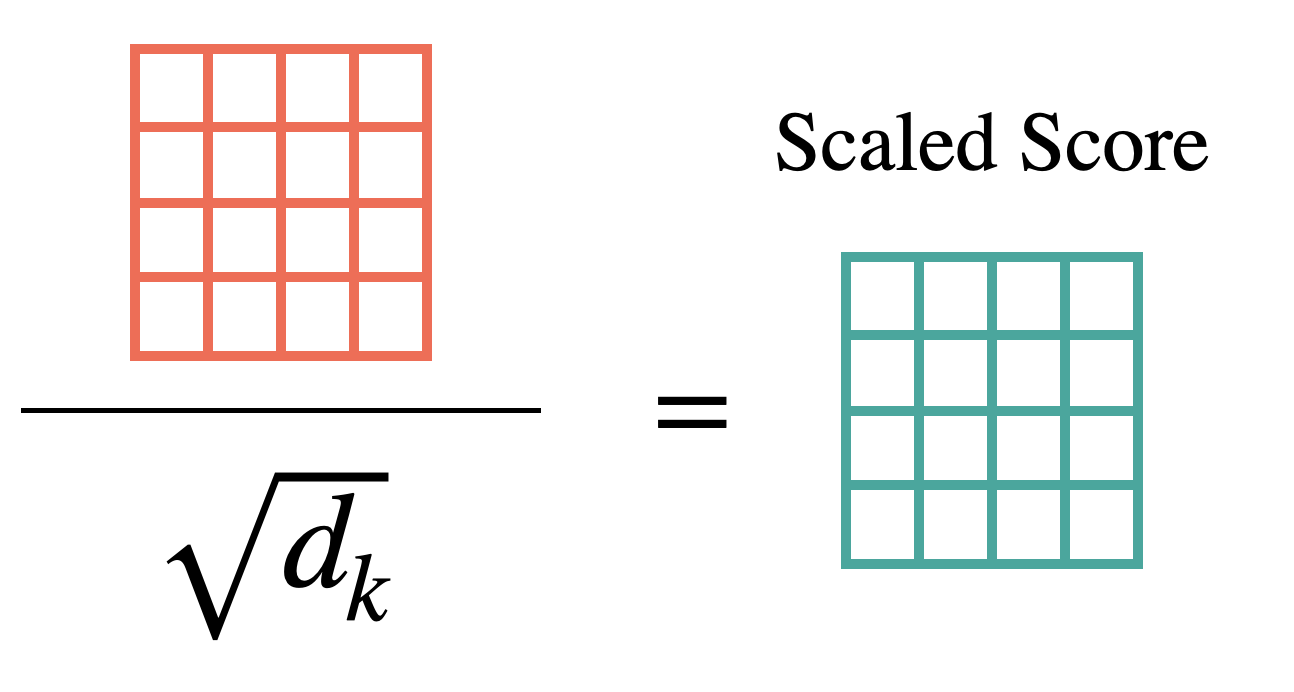
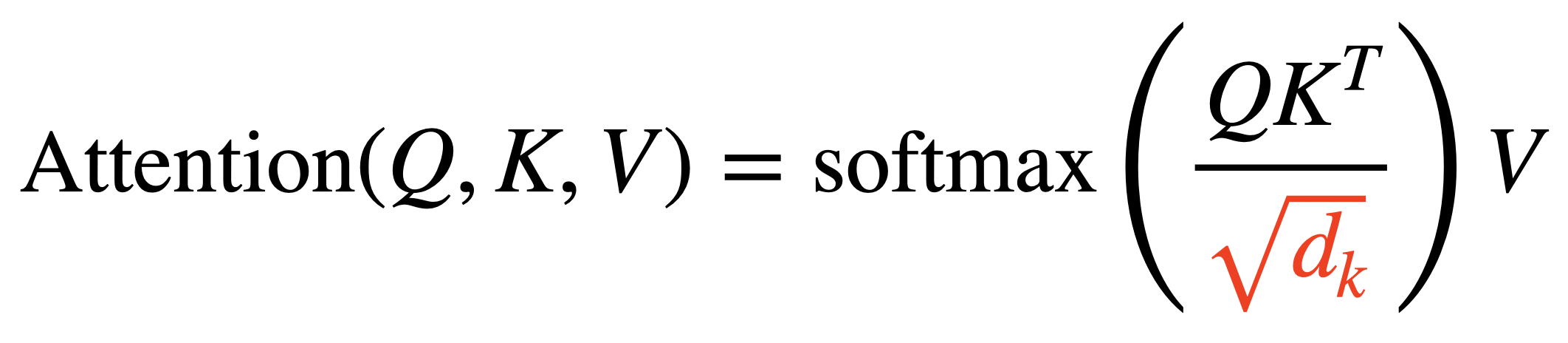
Query와 Key의 내적으로 계산한 Score Matrix를 Query의 차원(Key의 차원과 동일)의 제곱근으로 나눠준다. 이는 좀 더 안정적인 학습이 이뤄지도록 하기 위해선데, 내적의 특성 상 문장 길이가 길어질수록 더 큰 숫자를 가지게 된다. 이 값에 Softmax를 취하게 되면 큰 값을 가지는 특정 값만 살아남게 되고 나머지 값들은 완전히 죽어버리는 과도한 정제가 이뤄진다. 이는 gradient 값이 0에 가까워져 점점 사라지는 Vanishing Gradient 문제가 발생하는 원인이 되어 학습이 잘 이뤄지지 못하도록 만든다.
위와 같은 이유로 Softmax가 비슷한 범위 내의 값들 사이에서 이뤄져 Gradient 값들이 충분히 계산될 수 있게끔 Scaling Down을 하게 된다.
- Softmax of the Scaled Scores
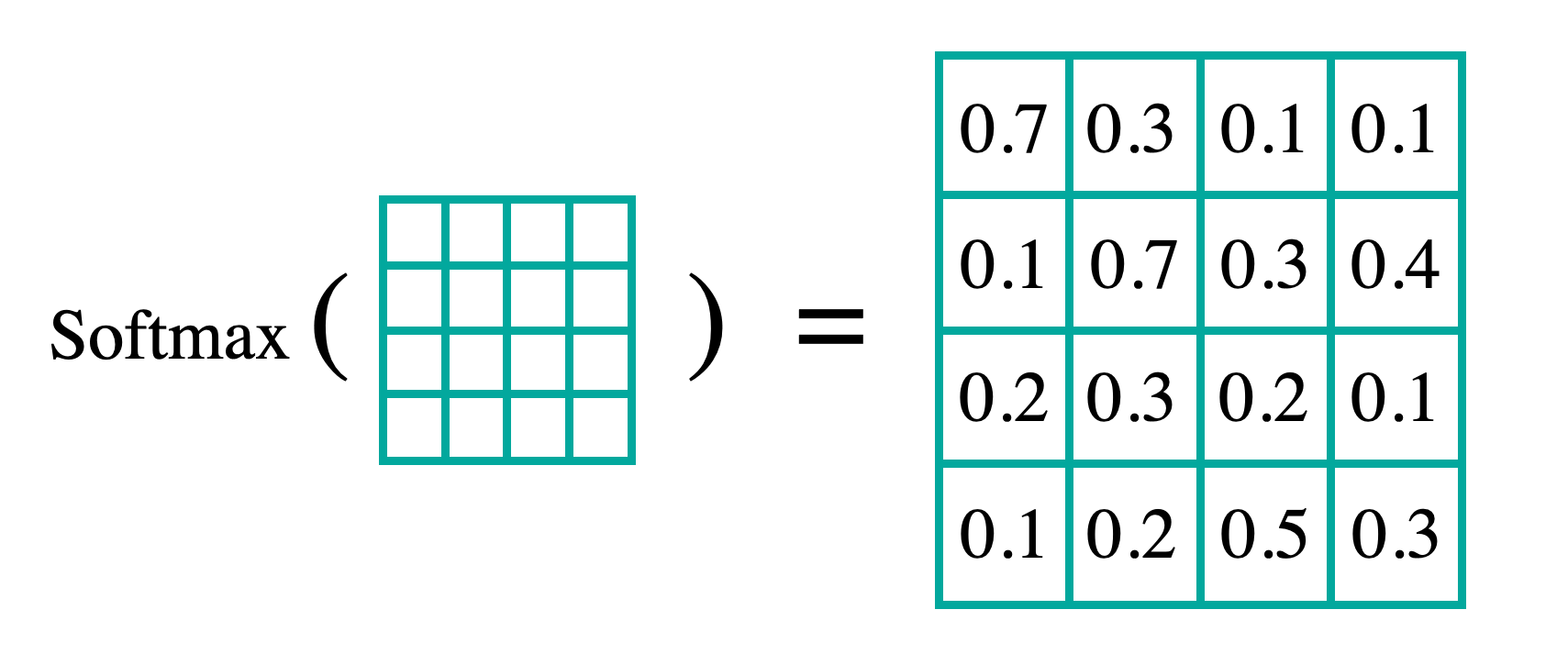
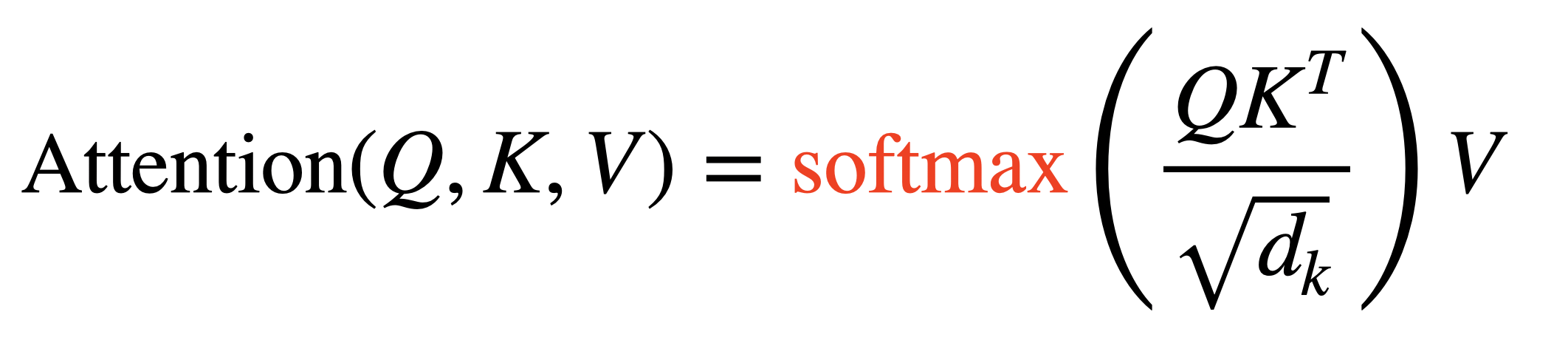
최종 Attention Weight를 얻기 위해 Softmax를 취해줘 Score 값을 0에서 1 사이의 확률 값으로 구성해준다. 이렇게 일정 범위 안의 숫자와 대응되게 변환해주어 높은 점수의 단어는 더 중요하게 낮은 점수의 단어는 상대적으로 덜 중요하게 파악할 수 있도록 한다. 이 과정을 통해 모델은 어떤 단어에 집중해야 하는지 보다 확신을 가지고 판단할 수 있게 된다.
- Multiply Softmax Output with Value
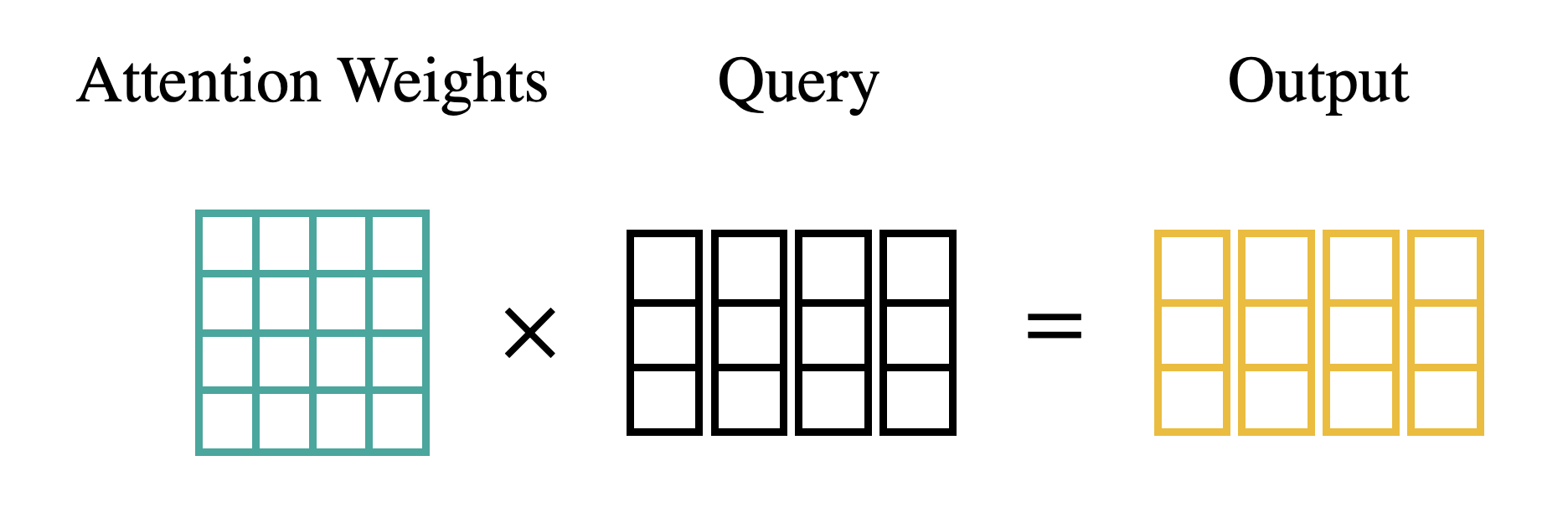
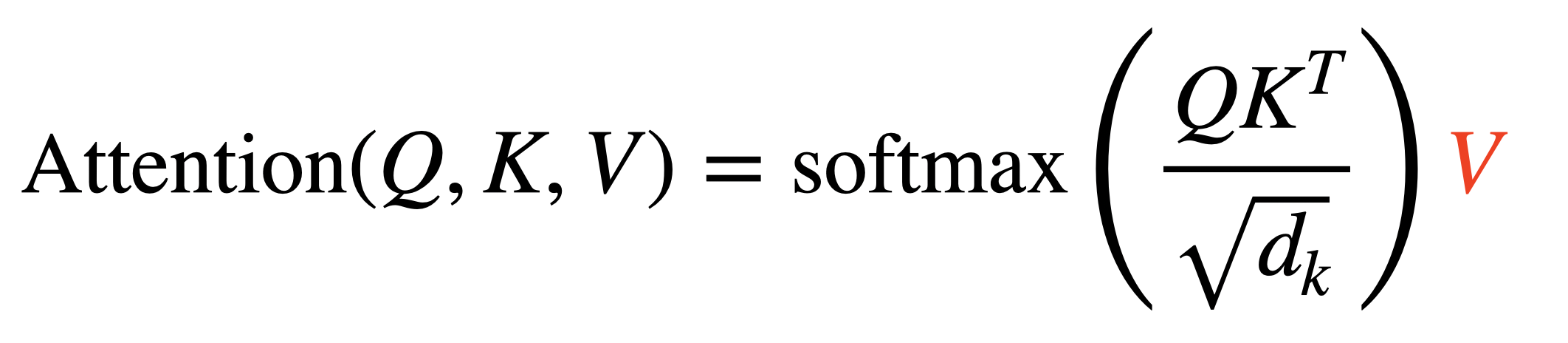
마지막 연산은 Attention Output Vector를 생성하는 것이다. 실제 단어의 정보를 Attention Weight에 더해주는 과정으로, Value 값을 곱해줌으로써 각 단어가 가지고 있는 정보를 다른 단어에 전달해주게 된다.
- Computing Multi Head Attention
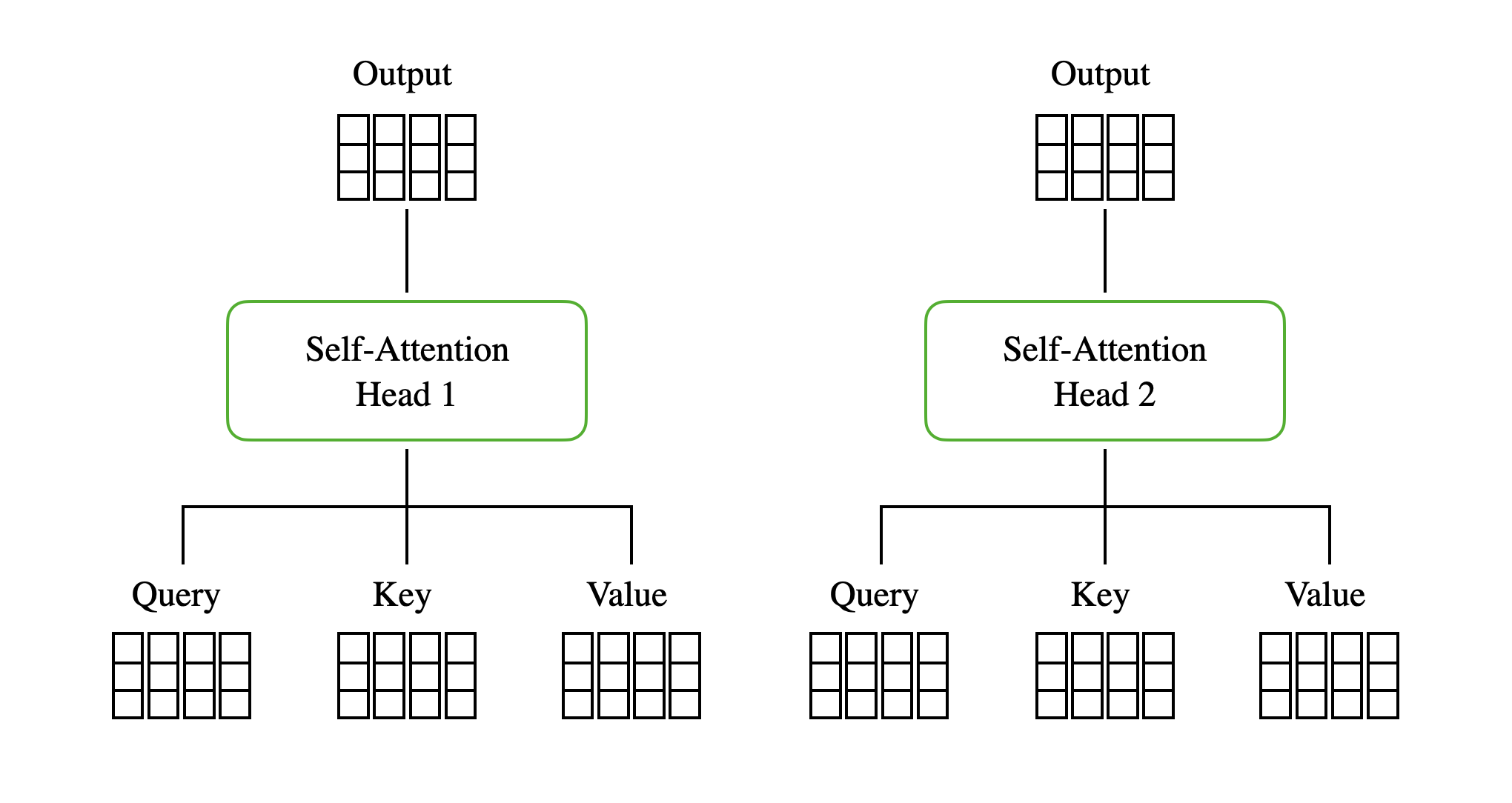
방금까지 살펴본 연산 과정은 Self-Attention 과정이다. Multi-Head Attention은 이러한 Self-Attention 연산을 한번에 하나씩 수행하는 것이 아닌 여러 개를 동시에 수행하는 것을 말하며, 하나의 Self-Attention 과정을 Head라 표현한다. 이때, Query, Key, Value 값은 Head마다 다른 값을 가지게 되어 Input Sequence의 다른 측면을 학습해 다양한 표현을 얻을 수 있다.
예를 들어, 1번 Head는 문장의 형태에 집중하고 2번 Head는 문장에 쓰인 명사에 집중하는 등 문장 내 여러 관계나 정보에 각각 집중해 좀 더 다양한 관점에서 모델이 학습할 수 있도록 하는 것이다.
- Residual Connections & Layer Normalization

Encoder의 Multi-Head Attention을 포함해 Transformer의 모든 sub-layer의 Output은 Residual Connection과 Layer Normalization을 거쳐 최종 Output을 생성한다.
Residual Connection은 Layer의 Output과 Positional Input Embedding을 합한 것으로, Output을 계산할 때 Input을 그대로 더해주어 Input 정보를 다음 층에 직접 전달한다. Layer를 통과해도 Input 정보을 유지할 수 있어 모델이 학습 과정에서 더 안정적이고 빠르게 수렴할 수 있도록 돕는다.
이어, Layer Normalization을 적용해 Output의 분포를 정규화하여 학습 시간을 효과적으로 감소시키고 모델 학습 또한 안정적으로 이뤄질 수 있도록 한다.
Position-Wise Feed-Forward Networks
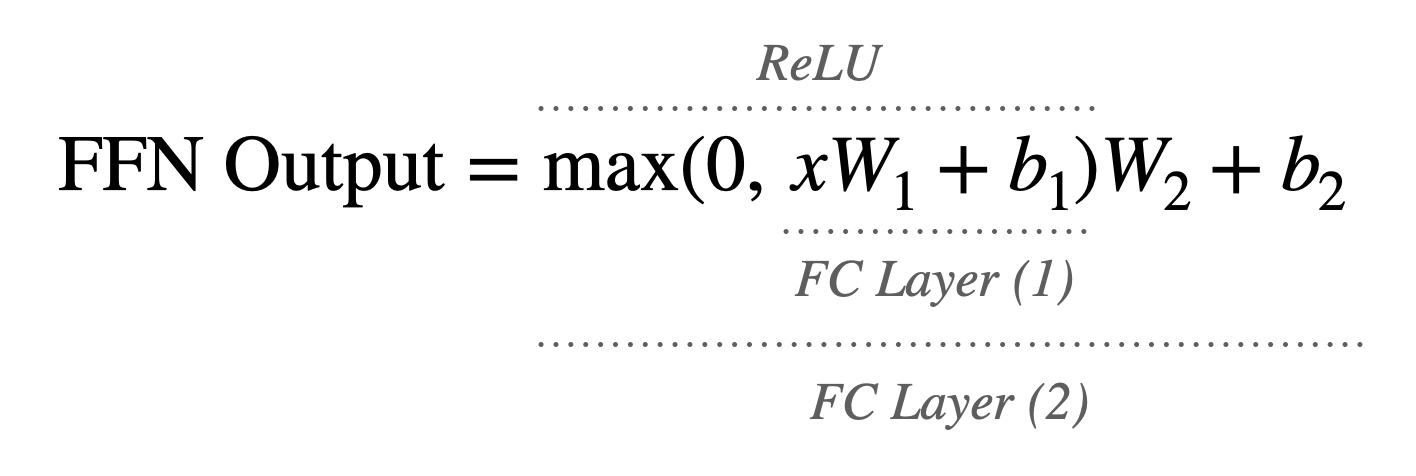
Encoder의 두 번째 Layer는 Position-Wise Feed-Forward Network이다. 각 단어에 대해 독립적으로 적용되는 Feed-Forward Neural Network로, 두 개의 FC Layer와 사이에 위치한 비선형 활성화 함수(ReLU)로 구성되어 있다.

FFN은 단어의 위치 특성을 학습하고 단어의 정보를 다른 단어들 간의 관계를 고려하여 업데이트 할 수 있도록 돕는다. 또한, 각 단어의 Input Embedding에 비선형성을 추가해 보다 복잡한 함수를 학습하고 다양한 Input 특성을 표현할 수 있도록 한다. 마지막으로 해당 Layer 또한 Residual Connection과 Layer Normalization을 사용해 최종 Output을 생성한다.
이렇게 계산된 Encoderd의 Output은 Decoder의 Input으로 사용되어 최종 Output Sequence를 생성한다. Decoder의 구조는 어떻게 되어있고, 최종 Output을 생성하는 방법은 무엇인지 알아보도록 하자.
Decoder
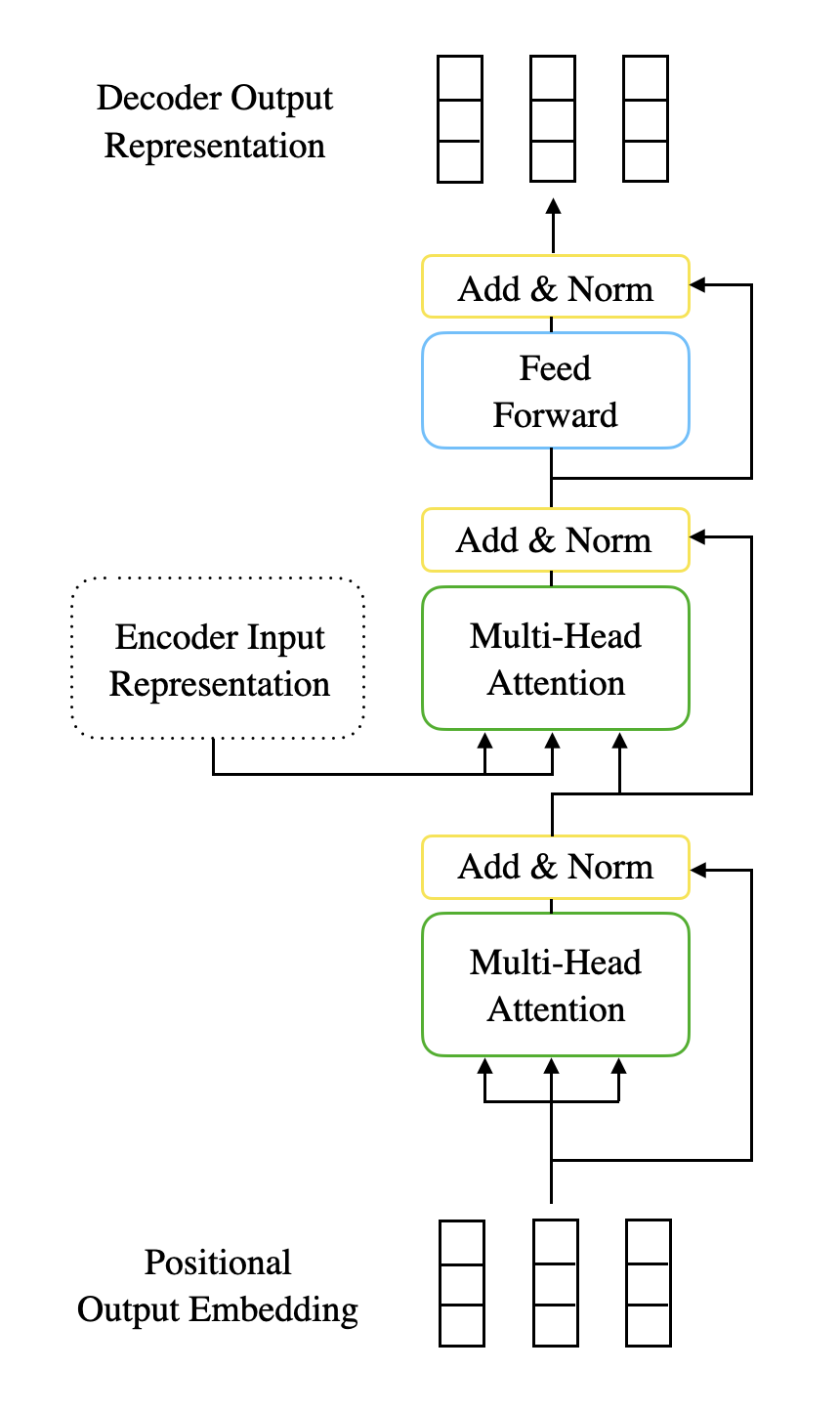
Transformer Decoder는 Input Sequence를 기반으로 새로운 Output Sequence를 생성하는 데 사용된다. Encoder와 마찬가지로 여러 개의 Decoder block으로 구성되며, 각 block는 3개의 sub-layer로 이루어져 있다.
Masked Multi-Head Self-Attention
Decoder의 가장 주된 특징은 AutoRegressive를 만족해야 한다는 것이다. 현재 생성되는 단어는 이전의 단어만을 참고해 생성되어야 한다는 조건으로, 미래 단어를 참고해 현재 단어를 생성할 수 없도록 구성하기 위함이다. 이를 위해 Masking을 적용한 Self-Attention Mechanism을 수행하게 되고, 이는 모델이 학습 중 잘못된 예측을 피하고 Decoding 과정에서 올바른 순서로 단어를 생성할 수 있도록 도와준다.
- Look Ahead Mask
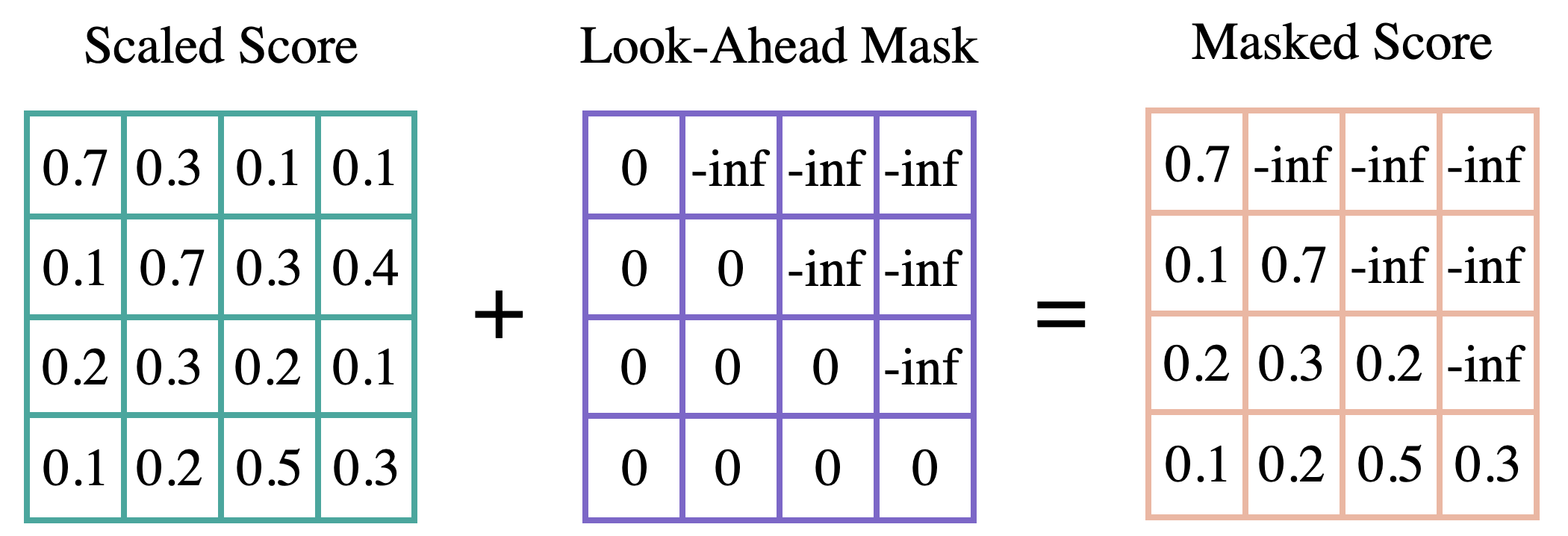
과거의 정보만을 활용해 현재 단어를 생성하기 위해 자신과 이전 단어 행렬엔 0을 자신보다 다음의 단어 행렬엔 -inf(negative infinity)를 적용해준다. 이를 Look Ahead Mask Matrix라 한다. 이렇게 생성된 Mask Matrix와 Self-Attention 연산을 통해 만들어진 Score Matirx를 합해 새로운 Masked Score Matrix를 만들고, 이후 Softmax를 취하게 되면 -inf 값들은 0이 됨으로 자연스레 모델이 미래 정보를 참조할 수 없게 된다.
Multi-Head Cross-Attention
두 번째 Multi-Head Attention Layer는 Decoder의 현재 상태와 Encoder의 출력 상태 간의 Attention을 수행한다. Encoder Input Representation에서 생성된 Query, Key와 Decoder의 첫 번째 Multi-Head Attention Layer Output에서 생성된 Value를 사용해 Multi-Head Attention을 수행한다. 이를 통해 Decoder는 Encoder가 생성한 Input Sequence 정보를 활용하여 새로운 Output Sequence를 생성할 수 있다.
Feed-Forward Networks
마지막 Layer인 Feed-Forward Network는 Encoder block의 FFN Layer와 유사하게 동작한다. 각 위치에서 독립적으로 입력을 처리하는 두 개의 선형 변환과 비선형 활성화 함수로 구성되며, token의 위치 특성을 학습하고 각 token의 정보를 서로 다른 token 간의 관계를 고려하여 업데이트 한다.
Linear Classification & Softmax
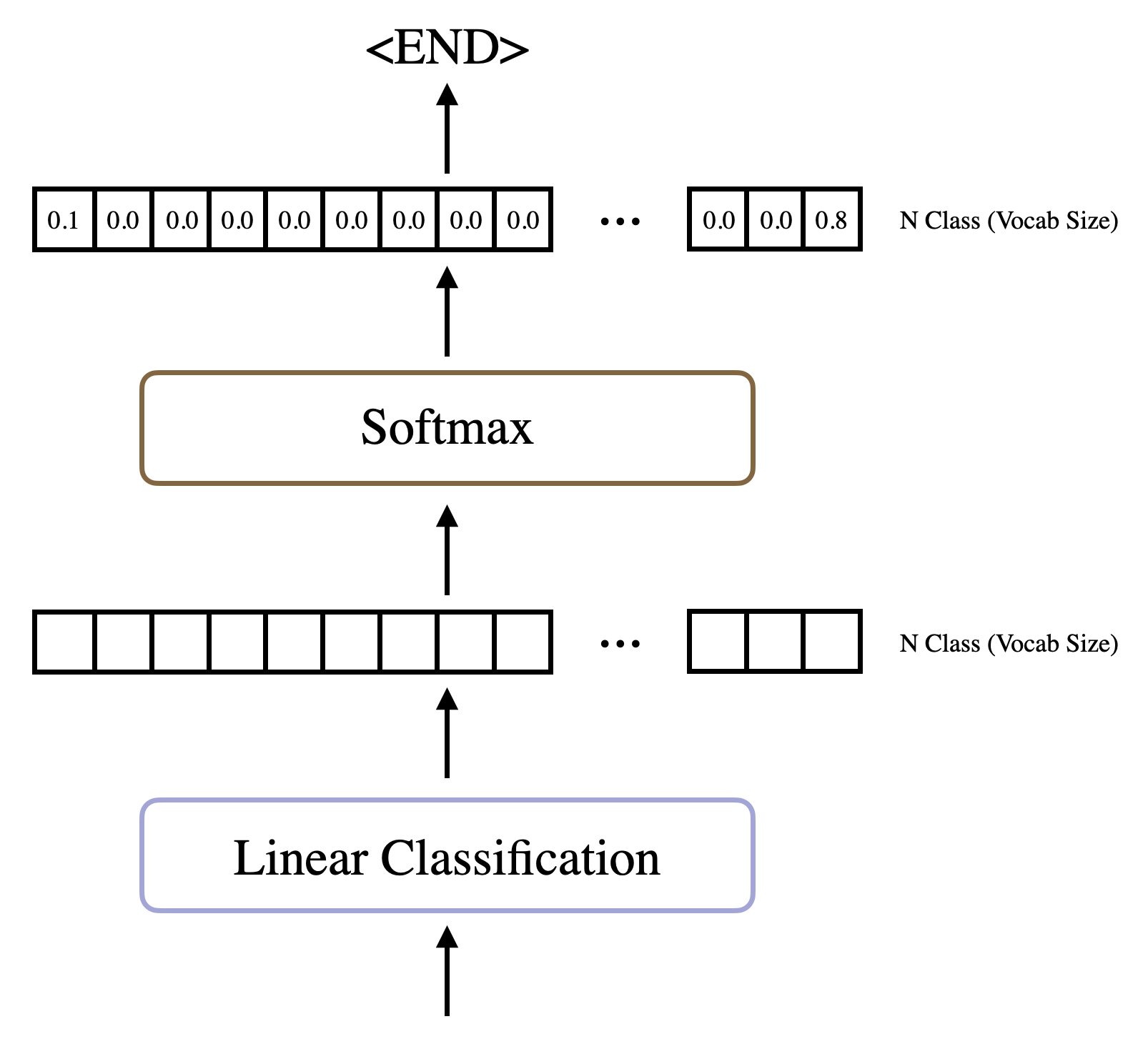
Decoder를 통과해 생성된 Output(각 단어의 의미를 포함한 고차원 vector)은 최종 단계만을 바라보고 있다. 바로 Classification을 위한 FC Layer(Linear)와 Softmax 이다. Linear Classification을 통해 단어 후보를 출력하게 되고, 이 벡터에 Softmax를 취해 단어가 최종적으로 선택될 확률을 출력하게 된다. 이 과정을 거쳐 나온 가장 높은 확률을 가진 단어가 최종 Output으로 선택되고, 이 단어들을 합해 최종 Output Sequence를 출력하게 되는 것이다.
Conclusion
드디어 Transformer 모델을 공부하고 글을 작성했다! 이 논문을 작성하게 된 배경이나 모델의 학습 결과 등은 빼고 오로지 모델 구조에만 초점을 두어 작성했다. Transformer가 딥러닝에서 어떤 영향을 미쳤는지는 워낙 자명한 사실이라 다른 논문 리뷰와 달리 모델 구조를 중요하게 봐야겠다 생각했다. Transformer를 공부하고 글을 작성하는 걸 차일피일 미루긴 했지만 역시 모든 걸 마무리하고 보면 아주 뿌듯하다. 그리고 가장 중요한 Multi-Head Attention 구조를 공부하면 나머지는 비슷한 내용이 반복되어 생각보다 어렵진 않았다. 다음 글은 Transformer를 PyTorch로 구현한 과정에 대해 작성하려 한다. 논문 내용을 코드로 구현하는 건 처음이라 걱정되지만 이 글처럼 마무리하면 뿌듯할테니 천천히 작성해보려 한다.
💡 Reference
1. https://arxiv.org/abs/1706.03762
이 글에서 가장 많이 참고한 글 입니다! 그림과 함께 Transformer 모델 구조를 설명하고 있어 이해하는 데 많은 도움이 됐습니다.
3-1. https://www.blossominkyung.com/deeplearning/transfomer-positional-encoding
3-2. https://www.blossominkyung.com/deeplearning/transformer-mha
Positional Encoding 과정을 좀 더 살펴보고 싶다면 3-1 글을 추천합니다.
4. https://velog.io/@jhbale11/어텐션-매커니즘Attention-Mechanism이란-무엇인가
'📒 Jero's Review > Paper' 카테고리의 다른 글
| Three Scenarios for Continual Learning (0) | 2024.06.12 |
|---|---|
| Show and Tell: A Neural Image Caption Generator (1) | 2024.05.10 |
| Sequence to Sequence Learning with Neural Network (0) | 2024.05.04 |